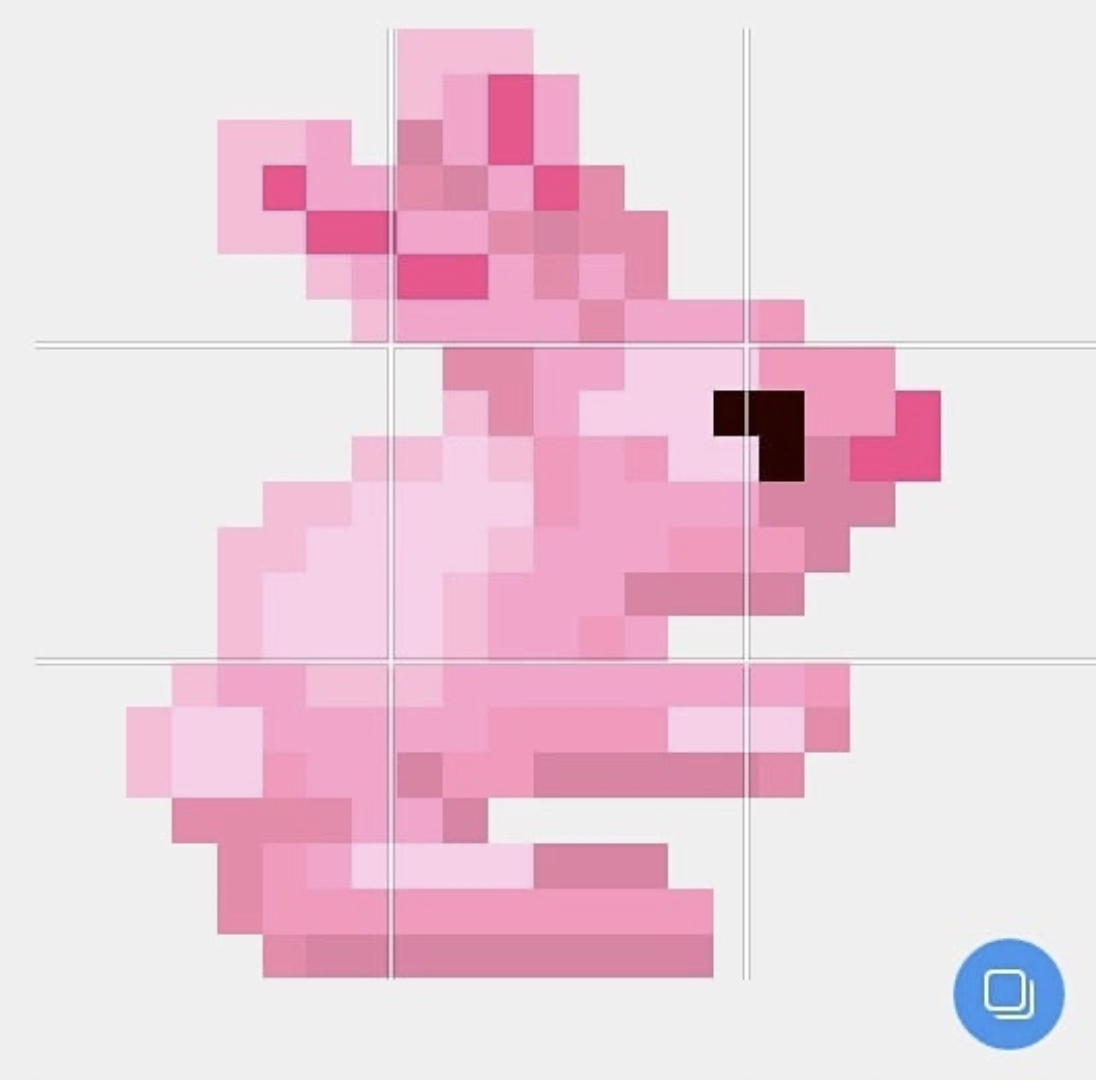
So, as we know it, loco means crazy. The prop also has a somewhat unique description. What does it actually do? Or is it just a normal prop, like the other props from the Easter Booster?
Here’s the image of the prop :

So, as we know it, loco means crazy. The prop also has a somewhat unique description. What does it actually do? Or is it just a normal prop, like the other props from the Easter Booster?
Here’s the image of the prop :
I think when you stand near it, it would some times get angry at you. I’m not sure but that’s what I heard it does.
It takes a while but, if you run back and forth past it it will eventually trigger and turn into a cooler and scarier bunny. Have a look at these images
Hmm, is world access needed?
No. Just walk past any bunny loco to see it. If you’d like I can let you do it to mine
Everyone around the world would be able to see how crazy the bunny is?
Yeah. Want to test it out? I have a bunny
Nah, I don’t have time ingame atm. Thanks for informing me. I thought it was just a simple looking prop. Also, does it produce any sound?
It does. It sound like a chirp or something. It’s a hard sound to explain. I’ll try to find a clip
Where i can find it?
check world BUNNYGOESCRAZY
Idk why the quality dropped but this is what it looks like
![]()
how to make it crazy? idk moving around for how many minutes or idk
It’s a pretty rare occurrence and it looks just like in the images posted above. It happens randomly, I must have passed by it like over a hundred times for it to reveal the demon inside of him just once lol. Not gonna lie, it kind of scared me when it did happen since it made some weird sound as well, but yes it is possible.
There is a world with a bunny in it for testing reasons. “BUNNYGOESCRAZY” is the world name if you’re interested.
Edit: sorry I just realized somebody mentioned this above already T.T